The art of debugging
Q: "Hey chatGPT, why is my code not doing the right thing? What should I do to solve it better?"
A: Some low quality surface level answer
Hmm that wasn't super useful. I'm still stuck. I'll ask my senior.
Q: "Hey Senior Developer, I keep running into issues and don't know how to solve them. Do you have any debugging advice"
A: "So this is how you use the debugger..."
Hmm I already knew how to do that…
Intro
With the rise of LLMs, I have been asking myself, what would make me useful in a world where code can be written by a machine? How can I make sure that I’ll be able to continue to work on fun and challenging problems, even if the world of software radically changes?
"If a man empties his purse into his head, no man can take it away from him. An investment in knowledge always pays the best interest." - Benjamin Franklin
When investing, it's important to make sure that your investments have good returns. Similarly when learning, it's important to spend time learning things which will have the most yield.
So what should I invest in so that, no matter how the technical landscape changes, I will still be able to afford my base needs for survival, mainly a $5 box from TacoBell, and also so that I can continue working on fun, interesting, and challenging problems without being replaced by a machine, or simply someone better than me.
Well, the best investments are in your fundamental skills. So what are the fundamental skills of software developers?
The Art of Debugging
Debugging is the process of investigating software defects to find their root cause(s). It is a diagnostic process.
The cognitive skills that facilitate effective debugging are problem solving skills that can be applied in many, perhaps most, other domains. Debugging is more than a thing that only software engineers deal with. It's a process that anyone is able to use as a problem identifying and solving strategy.
As mentioned by David Agans book Debugging: The 9 Indispensable Rules for Finding Even the Most Elusive Software and Hardware Problems, people who excel at debugging naturally follow his 9 rules which include:
- Understand the system
- Make it fail
- Quit Thinking and Look
- Divide and Conquer
- Change one thing at a time
- Keep an audit trail
- Check the Plug
- Get a fresh View
- If you didn't fix it, it ain't fixed
The book recommends printing a poster of rules, and hanging them up to remind yourself of it, but, one of the key problems I ran into when reading this book is that it is not easily actionable and not all rules always apply. Making it an easy to read, then forget, book.
The objective of this post is to walk you through a process designed around David’s 9 rules, along with a few extra tricks from the checklist manifesto that are thrown in to help make sure that nothing critical is forgotten, time is saved by avoiding common pitfalls and working in circles or aimlessly.
Why Do It?
Before we begin, I think it is extremely important to mention that adding processes to your life often seems like a great idea at first, but over time you find yourself not following them. I think this is usually because it was not natural to begin with so it's hard to force yourself into creating a habit. Or, it's because the process did not create enough value to make you want to follow it.
So fundamentally, we should do nothing that is not natural and we should find ways to enhance what is natural.
While some of these steps can feel like they are slowing you down, I would argue that in the long run they are beneficial and worth adding into your software processes. There is nothing worse than wasting your day going in circles or temporarily fixing something only for it to appear again later because you didn’t correctly identify the root cause.
There are 8 steps to this process which I use to protect me from temporarily fixing bugs or breaking other parts of my system. Additionally, the process helps me dig in and understand things better and at a top down and bottom up view.
0: Open the Checklist
In the airline industry, pilots use checklists to ensure that they don't make mistakes or stress out and do the wrong thing. It's extremely easy to jump to conclusions because you think you know exactly what the problem is, start pulling levers, knobs, and pushing buttons to realize you have either accomplished nothing and the problem still exists, or you have done something harmful and the problem still exists.
This checklist exists to help you stay on track, and not fumble around and go in circles. It keeps you accountable and focused on getting the job done. Which in turn helps you finish your work faster and more effectively. I have my checklist open while I work on the problem. Keeping it visible makes it easier to stick with and remember where I am.
It is surprisingly easy to forget this step, since there is no checklist to open your checklist. When you realize you forgot (and you have already wasted a few hours on a bug). Just open it and start from the beginning. After a while you will stop forgetting it.
Feel free to copy it and add it to your notes for your own use.
Title: Solving a Bug
Use: When solving a bug
Type: read-do
Date: 03/24/2025
Checklist
- [ ] Stop thinking - Make an audit log
- [ ] Read the bug
- [ ] Make it fail and record steps
- [ ] Understand the system
- [ ] Simulate the failure with a unit-test
- [ ] Identify the cause of the failure
- [ ] Fix the root problem
- [ ] Follow the steps to make it fail
- [ ] Remove the fix and watch it fail
1: Stop thinking - Make an audit log
In the airline industry, pilots use checklists to ensure that they don't make mistakes or stress out and do the wrong thing. It's extremely easy to jump to conclusions because you think you know exactly what the problem is, start pulling levers, knobs, and pushing buttons to realize you have either accomplished nothing and the problem still exists, or you have done something harmful and the problem still exists.
It can be tempting to try to fix the problem "quickly" hoping in vain to eliminate the bug’s underlying cause. This almost never works, and when it does it's generally only fixing the symptom, not the cause.
This step has only one goal, it is to make you stop, take a breath, and get in the mindset to fix the issue systematically. So that you aren't spending hours, days, and weeks struggling in vain futility with hasty, non-systematic approaches. In the end, those who thus struggle almost always wind up embracing some form of record keeping in order to finally find the root cause, or simply avoid checking the same place in the code base over and over again..
Though it might seem counter intuitive at first, this is the fast way to resolve any bug, and guarantee you won't create a new one in the process.
It also has some additional benefits:
- It lets you follow the flow of your thought process.
- It lets you keep track of why you made certain changes, so that as you learn more about the system you can come back to rethink what you did earlier.
- It can help prompt new ideas by looking back and being able to combine thoughts.
- It keeps you from accidentally leaving in code you didn't mean to.
I like to use Obsidian, it's a note taking app that lets me make templates easily. I have an audit log and a checklist that I like to use in tandem with one another. I will make a bug note, apply the template, and then I'll be able to start digging in and really looking into the bug. One thing to note, processes can be broken when it makes sense. If it turns out the bug was legitimately an easy one, you can delete this just as easily as you made it and lose nothing while still protecting yourself from some nightmare debugging scenarios.

In these notes, you can see we have an Audit Log, right now I like to use five fields, Id, Action, Note, and Context. In some cases keeping track of date and time can be helpful. But, when you have an audit log like this, it makes it easier to take clear notes, and encourages writing down thoughts that may not always seem to be useful, but might end up having a lot of value down the road. Additionally, I like to have a context field, in which I put the names of the files that are associated with those thoughts or actions. This makes it really easy for me to look back at what I did quickly without losing track of what I was doing and where I was doing it.
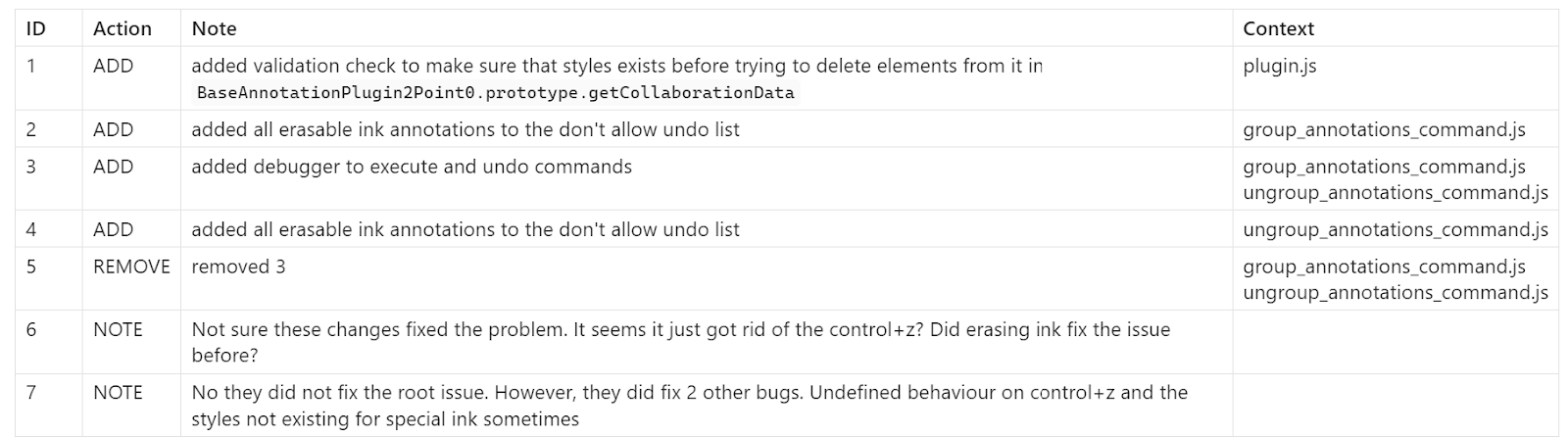
Here is a nice example of the audit log being helpful to me. When I went back through my logs, I was able to remember that the Class that I was working with was not getting checked for. This prompted me to dig in elsewhere in the code and see if we have any scenarios where this might also be the case. I quickly found out, because of the audit log, that the code generally just does not take into account the Class that was being modified. This is not something that could have been easily found. It would have been assumed that we just needed an “if statement” where the bug occurred, but having these logs helped find the root of the problem, which was the lack of support around the Class.
Audit logs are extremely important because they force you to pause and systematically look at what is happening and examine your thoughts in a way that can help you find the bug. They additionally help you to go back, and combine ideas, or remember trains of thought that you were going down and should potentially revisit.
2: Understand the Bug
Before diving into solving a bug, it's crucial to understand it thoroughly. Taking the time to identify what's going wrong and why it matters can save you a lot of time in the long run.
You may be thinking: "Why is it so important to fully grasp the problem?" The most obvious reason is that you want to ensure you're solving the right problem. It’s easy to hear about an issue, assume you know what’s causing it, and jump straight into fixing it. But sometimes, you might end up fixing something that wasn’t actually a major concern. It’s not a huge deal, but it highlights a more important question: Is this bug even worth solving?
As a developer, your time and resources are limited. It’s essential to focus on the issues that truly matter. The more you understand a bug, the better you can decide whether it’s worth your attention, or if it’s something that can be safely ignored.
For example, when I was working on a bug related to SMART's transition from Notebook to Lumio, it initially seemed like a trivial issue. The bug in question involved special ink types in Notebook files, which Lumio only supports when teachers upload .notebook files. At first glance, it seemed like something we could easily overlook. But by asking a few simple questions like "How many users actually use these special inks?" and "How many are importing them into Lumio?" I realized that the issue affected only a small number of users.
So why did we decide to address it? Because Lumio is aiming to replace Notebook, and teachers rely heavily on reusing lesson plans. If even a small part of a teacher’s lesson plan breaks during the transition to Lumio, we risk losing their support. And once we lose a teacher, it’s much harder to win them back.
Understanding the context behind a bug helps you make a stronger case for whether or not to solve it. It also helps you dive into the solution with a clear understanding of its importance for stakeholders. With this context in mind, you can ask better questions and more effectively identify the root cause of the problem.
Key Questions to Ask
Before jumping into fixing the bug, take a step back and ask a few important questions:
What exactly is the defect?
- Clearly define the problem. What is happening, and what should be happening instead? This will be the foundation for all your troubleshooting.
Why is this bug important?
- Understanding the bigger picture helps you prioritize. Is it a minor issue with little impact, or is it something that could affect a larger group of users or business outcomes?
Technical Questions to Consider
Now that you’ve gotten a clearer picture of the bug, it’s time to start asking more technical questions. These help ensure you’re not making any assumptions about the problem:
Are we making any assumptions about this bug?
- It’s easy to assume we know what's happening, but it’s crucial to test those assumptions. Double-check to make sure your understanding of the issue is correct. Double-check any notes that were left on the bug report to make sure that you aren’t basing any ideas on false assumptions.
How old is this bug?
- Is this a new problem, or has it been lingering for a while? If it’s a recent bug, can you pinpoint the exact change that introduced it?
Is there anything obvious you might have missed?
- It’s easy to overlook simple things, like whether your VPN is on, or if the correct flags are set to enable a specific feature. Make sure you check the basics before diving deeper.
Finally, after you jot all that down, it's also helpful to add any videos, links, documentation, or images to your audit notes in the about section so that if you come back to this issue later you will not have to dig around to learn the context. Most companies use things like GitLab, Jira, or other dev ops tools. I recommend also uploading your notes to the commends in your bug, or pr.
Before you start debugging, take the time to understand the issue from all angles. The better you understand the bug, the more effective your solution will be. Clarify what the problem is, why it matters, and what steps you need to take to address it. Only then should you dive into the technical details. This approach not only helps you solve problems more efficiently, but it also ensures you’re working on issues that truly have an impact on your users and your business.
3: Make it fail
In the next step, you need to make the program fail over and over again in as many different ways that you can find.
There are a few reasons why this is important, the main one is so that you have reproducible steps to make the issue occur, so that, after you have added your fix, you can follow these steps to prove that the issue no longer occurs.
Usually the bug report will include steps to make it fail, but following these and making sure they work are important. It's helpful to do this to find any files or states that the system needs to be in or have to fail.
What’s more, figuring out how to make it fail using different flows allows you to more quickly find a root location where the issue starts to occur, or it lets you find the different flows..
This highlights a critical insight: there may be multiple execution paths through the code that can trigger the same root cause. Identifying all such paths is valuable, as it reinforces the importance of thoroughly exploring different code flows to fully understand the failure and ensure robust detection.
From there you can create simulations and hard-code what is needed to make a specific part of the code fail automatically without needing to follow the entire system process. This is great because now not only do you have a way to automatically and rapidly make it fail, you can increase confidence in your fix.
In the case of importing files from notebook, I was able to follow two distinct flows, one which undoes the group function, and one which un-groups the objects. Both of these functionally did different things even though they seemed like the same concept.
As a result of identifying the different methods for causing the system to fail, I found that the specific bug had two distinct ways that it could fail. Both followed their own flows and had different desired outcomes.
In this case, when the user pressed control+z we wanted to ignore the undo-group action because for Ink, if the user erases part of it, the undo action has odd behavior. The second flow was for the ungroup action, which works for erased ink and ungroups everything.
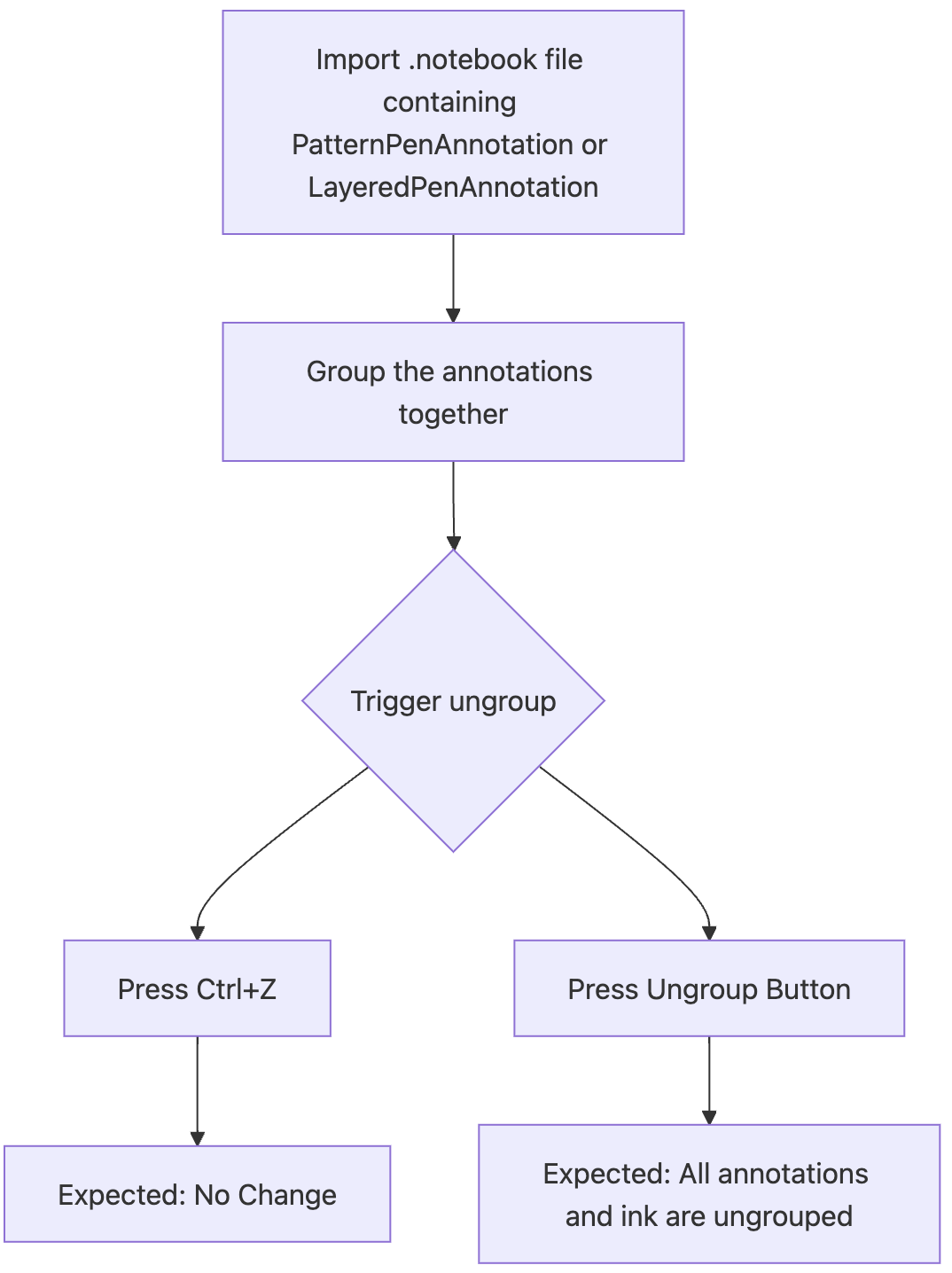
Additionally, in doing this I was able to further ask the question, why don’t we utilize the ungroup function so that the user can press control+z and expect the annotations to become ungrouped.
Now that I was able to watch the issue occur and all the different ways it was able to do so, I was able to simulate the failure knowing the root causes of the issue.
Pressing ungroup or control+z for groups containing the PatternPenAnnotation, or the LayeredPenAnnotaiton would cause Lumio to fail. This was something I could do over and over again, and even simulate.
4: Understand the system
Now that we have a clear understanding of the bug, the next step is to develop a deep understanding of the surrounding system. This is essential for two reasons: it allows us to isolate the bug from the broader system, and it helps us determine whether the unexpected behavior is actually a bug or simply the system functioning as designed. The fastest way to gain this knowledge is by consulting available resources, reading the documentation, reviewing design documents, and speaking with those who have worked directly on the system.
Once you have a foundational grasp of the system, you can begin mapping out its structure: identifying key components, understanding how data flows through them, and determining which parts can be isolated for more effective debugging. By building this mental road-map, you will be in a much better position to track down the root cause of the problem efficiently.
A developer at my company showed me a cool trick for building these mental road-maps. Using tools like mermaid.js, you can make quick, easy to follow code flows, sequence diagrams, and architectures of the system that you are working in.
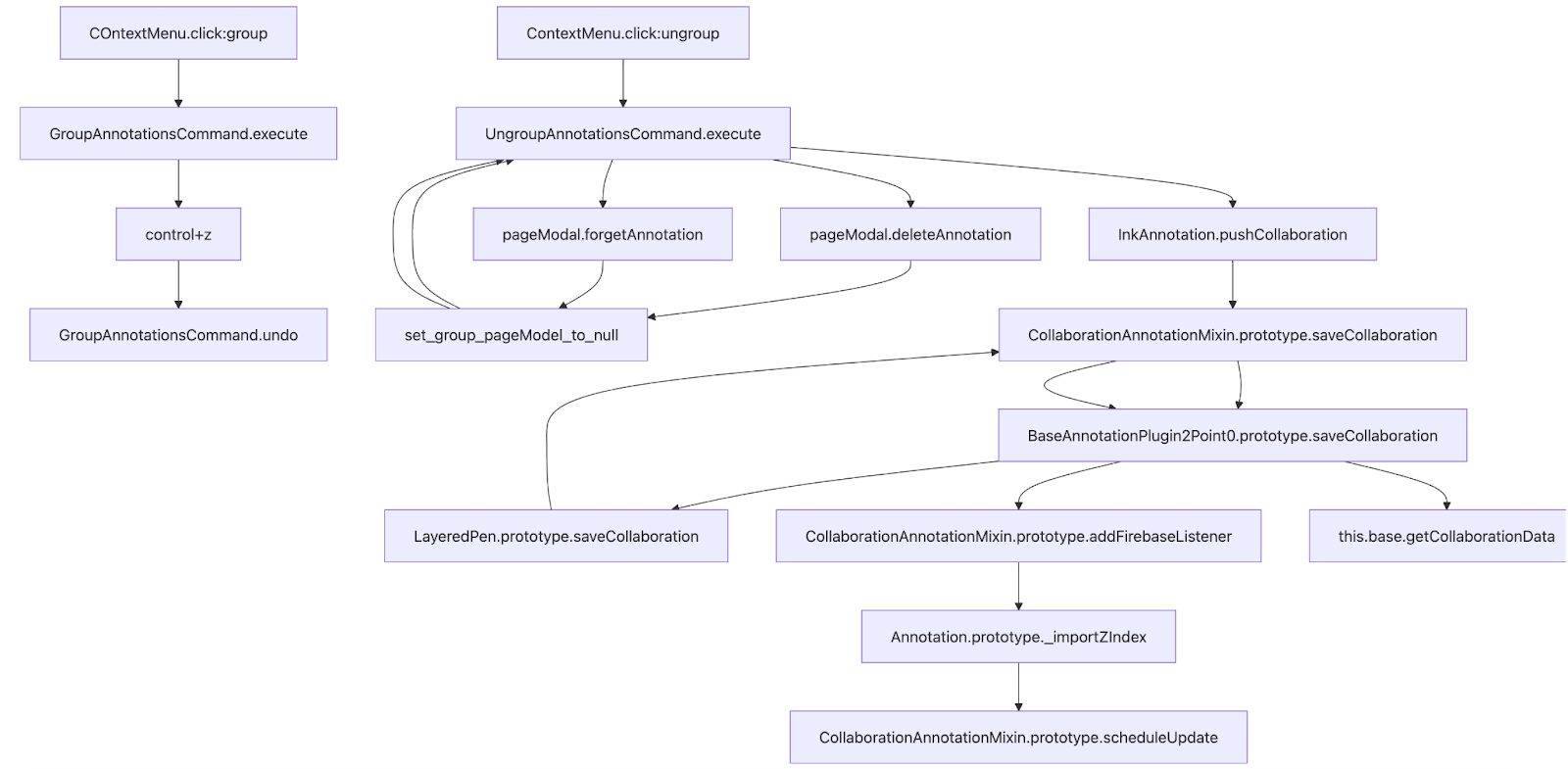
With a road-map like this you are able to identify bottlenecks, see any duplicated code, and understand how changes in one location may impact other systems. Additionally, it gives us a much better way to create unit tests to make sure that we can make a simulation of the bug and write a test case for it. In this specific scenario we can make two unit tests in both GroupAnnotationsCommand.execute, when the user presses control+z and UngroupAnnotationsCommand.execute. Every time we run these tests, we will be able to verify that the bug exists here, and then later prove that we fixed the issue.
Finally, understand the tools that you have available to search with. Do you have a debugger? Can you use logs? Are you able to make and test API calls easily? Can you see the stack trace of when the failure occurs? Does the program even crash?
Jot down in your audit log the key locations that you may need to look at to more readily identify the root cause of the symptom. The longer you spend working on a system the less time you have to spend making sure you understand it. But you should always be writing down the places you need to, or have already looked at so that you don’t end up like a dog chasing its tail.
As a side note, finding these tools and methods to understand/debug things more effectively and faster are extremely beneficial to your ability to solve problems. You should always be asking around and looking for anything that can enhance your ability as an engineer.
5: Identify the cause of the failure
As David Agans wisely put it, the measure of a good debugger is not how quickly you make a guess or how clever your guesses are, but how few bad guesses you actually act on. Which, on a side note, happens to follow along with the 10th principal of the Agile Manifesto, which states that simplicity is key, and maximizing the amount of work not done is essential!
When you have a hypothesis about the bug, test it. Don’t just assume; prove that your guess is correct. For example, if you suspect bad input is causing the issue, test both good and bad input to try and force the failure. If you think the data is getting corrupted, focus on testing data that’s easy to track and observe using a debugger.
Think of debugging like following a trail. Imagine a factory is spilling pink goop into a river. If you know where the river turns pink, you can trace the flow upstream to find the root cause of the spill. Similarly, by understanding the system well, you can trace the bug back through the code until you find the point where the issue stops, leading you to its source. Following this mindset, you can watch the issue occur. In the specific bug I was working on, the system would fail when we called the function to update the system because a variable that it was dependent on would not exist. The easiest thing to do is to just check the variable exists before running the function, but this would only be fixing the symptom of the failure not the root cause. This is where exploration starts becoming important and making visual representations of the system can be beneficial. You can move upstream looking for where the pink goop appeared. In this case, we are looking for where the variable we are dependent on is set to null and devise a method for making sure that won't be a problem.
While you're testing your hypotheses and trying to find the root cause, it’s important to change only one thing at a time. If you're adjusting system variables to narrow down the cause, modify just one variable at a time. This makes it easier to identify the real cause, you may update one variable here, then update another one elsewhere then test the system, you may falsely attribute the fix to the wrong thing and if you weren't keeping an audit log, you’ll forget you even changed the first variable.
I’m Stuck!
If you’re still stuck, take a break. Sometimes, stepping away from the problem can help you come back with a fresh perspective. Talk to experts or describe the problem to someone else. Often, explaining the issue can trigger new insights. Or, try working on something else for a while. When you return, you might approach the bug from a different angle and find the solution.
6: Fix the root problem
At this point, you need to pause and ask yourself: did you fix the problem, or did you fix the cause of the problem? If the issue is that a variable is being set incorrectly, did you address why the variable is being set wrong, or did you simply check if the variable was set incorrectly and prevent the code from running? Just because the issue no longer exists doesn’t necessarily mean you’ve fixed the root cause.
It’s incredibly easy to address the immediate problem without solving the underlying cause. For example, imagine your refrigerator is leaking water onto the floor. The problem is the water on the floor. You could wipe it up and temporarily fix the problem, but the refrigerator will leak again, and you’ll face the same issue.
One way to ensure you’re fixing the root cause is by asking yourself whether you actually saw the bug fail and whether you fixed the reason behind the failure. Just witnessing the problem doesn't necessarily mean you identified the cause. Make sure you observe the bug’s root cause firsthand. Once you’ve done that, you can address the actual problem.
That said, sometimes fixing the root cause isn’t feasible. You might discover that another part of the system depends on the issue, and fixing it could break something else. In such cases, simply changing it might be risky because of the interconnectedness of other components.
When you encounter this, having a deep understanding of the system is crucial. It allows you to assess whether your fix introduces any risks, and if it does, you can develop a safer, more effective solution. In the worst case, understanding the system well will help you justify fixing only the symptom. If fixing the root cause would cause more issues than it solves, applying a temporary fix, like duct tape, is the best solution for that specific scenario.
This was exactly the case with the bug I was working on. The variable my code was dependent on was being set to null within a thread, where other code expected the variable to be null. With this knowledge of the system, I was able to confidently say that simply checking if the variable exists before making the call was the correct solution for this issue.
7: Follow the steps to make it fail
Now that you've fixed the bug, it's time to go back to your handy dandy audit log, and follow the exact steps to make it fail. If it fails, you definitely didn't fix it. If it doesn't fail, then maybe you fixed it. Or maybe one of the many small changes or tests that you made fixed it. It's important to know exactly what fixed the problem.
8: Remove the fix and watch it fail
Check your audit log. Remove everything that is related to the fix and make sure that the system fails. If it fails, then we know your fix was truly the fix. If it doesn't fail, then you didn't fix it. Just because the problem is not reproducing doesn't mean you fixed it. It just means it's not reproducing. Figure out how to make it fail and start the process over again.
9: Clarify your Final Thoughts
At this point, you will have fixed the bug. While this may seem like the easiest part, it is also one of the most important steps and it’s easy to overlook. Take the time to jot down your final thoughts in your notes. Reflect on the bug and the process you went through to fix it. Document any key insights or interesting observations that came up while working on the issue.
Be sure to include important details about why you made certain implementation choices when applying the fix. This step helps ensure that you capture the rationale behind your decisions and any context that might be relevant later.
Although this might not feel significant at the moment, it becomes incredibly valuable when you revisit the issue in the future, whether during a pull request review, while trying to understand past work, or when checking why certain changes were made. By reviewing these notes, you can refresh your understanding of the bug and the solution, which will help you maintain a deep understanding of the issue even months down the line.
Conclusion
So, why is this process better than simply jumping straight into fixing the bug? And how does it relate to the larger question of staying relevant in a world where machines can generate code?
In a world where LLMs and AI are transforming software development, one key factor that will always set humans apart is deep understanding and problem-solving. This process isn’t just about fixing bugs; it’s about building the fundamental skills that make you indispensable. By taking the time to understand the root cause of a bug, you are investing in knowledge that will pay off in the long run. The process forces you to think critically and logically, which are skills that machines cannot easily replicate. And so, in becoming good at this, even if the tools you use change, you will still have a good process for helping you think deeply and truly process and understand what you are working on.
This approach encourages you to create unit tests, ensuring your solution is reliable, and that the underlying systems remain stable in the future. It pushes you to document your work in a way that ensures you and others can refer to it in the future. These are all skills that machines can't take away from you. The ability to leave behind clear, detailed documentation and tests provides an ongoing return on your investment in knowledge.
You’ll also be fixing the root cause of the bug, not just applying quick patches. This is important because machines can fix symptoms, but they cannot yet trace complex problems to their source in the same way humans can. This is where your understanding of the system becomes irreplaceable.
Moreover, by having a checklist and a template to follow, you create consistency, which increases your dependability as a software developer, something that will continue to be valuable, no matter how the landscape evolves. The checklist gives you a repeatable, reliable process to follow, making your work more efficient and error-free.
Lastly, having an archive of audit data and documentation ensures you can look back on previous issues and solutions, building a knowledge base that you can use to tackle future problems with more context.
To answer the question from the introduction: the best investment you can make is in developing these fundamental skills. Understanding systems, solving problems, creating tests, documenting your work, and learning from past issues are all vital skills that will make you resilient in a future where AI plays a larger role in coding. In an ever-changing technical landscape, these skills will always be in demand, allowing you to continue working on interesting and challenging problems and maybe even enjoying a Taco Bell box along the way.